Greengrass V2のコンポーネントをデプロイしたら403 Access Deniesで怒られた
Greengrass V2のコンポーネントをデプロイしたら、エラーが出てデプロイ失敗した
com.aws.greengrass.componentmanager.exceptions.PackageDownloadException: Failed to download artifact name: 's3://xxx/xxx.zip' for component com.xxx.xxx, reason: S3 HeadObject returns 403 Access Denied. Ensure the IAM role associated with the core device has a policy granting s3:GetObject
コンポーネントの中でs3上のzipファイルをロードしてくる作りにしているんだけど、どうやら権限がうまくいっていないらしい。
色々調べたら、以下の記事が見つかった。設定が漏れていた。デフォルトではコアデバイスが S3 バケットにアクセス許可してないらしい。なので、コアデバイスのロールにポリシーをアタッチしてあげる必要がある。
以上。
cdkでnodejs(typescript)のLambdaを実装する時、そこに外部ライブラリを使うのかい?使わないのかい?どっちなんだい?
最近、projenを使ったcdkプロジェクトの構成ファイル管理にハマっています。 いままでは、pythonでLambdaを書いていたのですが、cdkはtypescriptで書いており、いっそのことLambdaもtypescriptで書いちゃおうと思ったのですが、外部ライブラリをimportする際に怒られる。
Error: Cannot extract version for module 'XXXX'. Check that it's referenced in your package.json or installed.
やること
package.jsonをhandlerのjsファイルにないので、yarn initでpackage.jsonを作って、dependenciesを追加する
$ cd {lambda実装したフォルダ}
$ yarn init
$ yarn add 'XXXX'
これでpackage.jsonファイルが作成されて、モジュールのdependencesも設定できる。\
ちなみに、最初は訳もわからず$ yarn add -D 'XXX'をしてしまい、devDependenciesに設定してしまったがために、yarn buildした時にdependenciesにしてねと怒られた。
SageMaker Studioのターミナルからawscliを使いたい
SageMaker Studioのターミナルからawscliを使いたいので、インストールする。
awscliのパッケージファイルをダウンロードして、SageMaker Studioのフォルダに置く
- curlが使えないので、ローカルにダウンロードしてnotebookでアップロードする。
AWS CLI の最新バージョンをインストールまたは更新します。 - AWS Command Line Interface
unzipする
unzip -u awscliv2.zip
インストールする
./aws/install
以上
jupyter labにあるipynbとpy拡張子のファイルだけtar.gzする
jupyter labで作業した後に、ipynbとpyの拡張子のファイルだけtar.gzしたいことがあった。 なぜなら、jupyterで作業しているとpngとかcsvとかhtmlとか色々出力してしまい、tar.gzする時それらがジャーマンスープレックスになってしまうから。 最初からgit使って、.gitignoreに書いとけよって話だけど、まーいいじゃない。
find ./ | grep "\.\(py\|ipynb\)$" |grep -v ".ipynb_checkpoints"| xargs tar czvf hoge.tar.gz
ポイントは.ipynb_checkpointsを排除してるところ。
node.js+AWS SDKでDynamoDBにデータ挿入
やりたかったこと
Amplifyで画面開発したのだが、デフォルトデータをDynamoDBに挿入しないと動かないので、初期のインストール時にデータをinsertしたかった。
サンプルデータの作成
- 定型のメッセージをDynamoDBに挿入するときに、dict型でデータを持っておきたかった。これは、テストコード流すためでもある。
- プロジェクトのフォルダ構造はこんな感じ。sample-dataというフォルダを作ってそこで管理
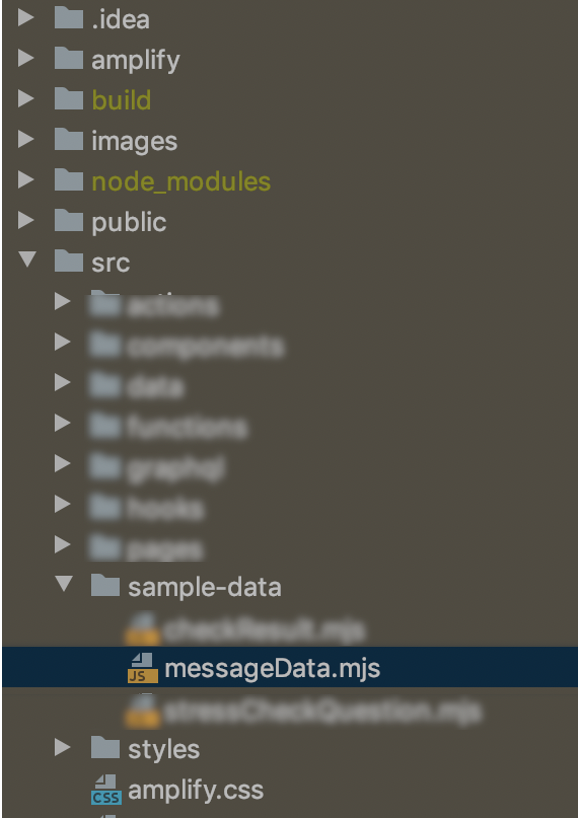
フォルダ構造とサンプルデータ - 拡張子は
.mjs。こうしないとうまくいかなかった。なぜかは話が深くなるからここでは書かない。以下参照。
- messageData.mjsの中身はこんな感じ
// messageData function createMessageData(id, a, message) { return { id, a, message}; } export const messageData = [ createMessageData( "id-a", "0", "やっほー、ボーっとしたいよ!" ), ];
データ挿入スクリプトの作成
import {messageData} from './sample-data/messageData.mjs'; import AWS from 'aws-sdk'; const aws_profile = process.argv[2]; //スクリプトの引数にaws configファイルのプロファイル名を渡す let credentials = new AWS.SharedIniFileCredentials({profile: aws_profile }); AWS.config.credentials = credentials; AWS.config.update({region: 'ap-northeast-1'}); const ddb = new AWS.DynamoDB({apiVersion: '2012-08-10'}); const message_data_tablename = 'messageData' //insert message data to DynamoDB for (let item of messageData) { let params = { ExpressionAttributeNames: { "#a": "a", "#message": "message", }, ExpressionAttributeValues: { ":a": { S: item.a }, ":message": { S: item.message } }, Key: { "id": { S: item.id } }, ReturnValues: "ALL_NEW", TableName: message_data_tablename, UpdateExpression: "SET #a = :a, #message = :message }; ddb.updateItem(params, function(err, data) { if (err) console.log(err, err.stack); // an error occurred else console.log("master data insert SUCCESS."); // successful response }); }
スクリプトの実行
- srcフォルダの1つ上のフォルダで以下を実行する
node --experimental-modules --experimental-json-modules ./src/install.mjs {対象のAWSプロファイル名}
困ったところ、感想
python statsmodelsでロジスティック回帰した
参考文献: - 手を動かしながら学ぶ ビジネスに活かすデータマイニング
動機
注意点
コーディング
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split import statsmodels.api as sm import statsmodels.formula.api as smf %matplotlib inline sns.set() df_6_4_1 = pd.read_csv("ch6_4_1.txt",sep="\s+") X = df_6_4_1[["d11","d12","d13"]] Y = df_6_4_1[["cvr"]] X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size=0.2,random_state=0) data = pd.concat([X_train, Y_train], axis=1) formula = "cvr ~ 1 + d11 + d12 + d13" link = sm.genmod.families.links.logit family = sm.families.Binomial(link=link) mod = smf.glm(formula=formula, data=data, family= family) result = mod.fit() print(result.summary()) y_pred = result.predict(X_train) plt.plot(y_pred,Y_train,'.')
出力
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: cvr No. Observations: 24
Model: GLM Df Residuals: 20
Model Family: Binomial Df Model: 3
Link Function: logit Scale: 1.0000
Method: IRLS Log-Likelihood: -7.0982
Date: Sat, 30 Oct 2021 Deviance: 5.4885
Time: 06:59:20 Pearson chi2: 5.51
No. Iterations: 6
Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -4.9468 5.487 -0.902 0.367 -15.701 5.807
d11 0.0024 0.001 2.513 0.012 0.001 0.004
d12 -0.0005 0.001 -0.767 0.443 -0.002 0.001
d13 -0.0002 0.001 -0.248 0.804 -0.002 0.001
==============================================================================

感想
- ちょっとだけ勉強になった気がする